

Forschungsprojekt KREEN: Zwischenergebnisse


von Marlene Groß
Nov. 26, 2024


Spurensuche im Datendschungel • Grafik: plusmeta GmbH, Viktoria Kurpas/Shutterstock.com
Seit Oktober 2023 arbeiten wir an unserem dritten Forschungsprojekt. Dieses wird gefördert durch das Wirtschaftsministerium Baden-Württemberg im Rahmen von InvestBW InvestBW.
Ziel des KREEN (“KI-Anwendung zur Recherche und Extraktion der Entscheidungsbasis für den nachhaltigen und Ressourcen-schonenden Betrieb von Maschinen und Anlagen”) -Projekts ist die Entwicklung einer KI-Anwendung, die bei der Recherche und Extraktion von Maschinen- und Anlageninformationen zum nachhaltigen und ressourcenschonenden Betrieb unterstützt. Die gewonnenen Daten sollen so aufbereitet werden, dass sie zwischen verschiedenen Systemen der Technischen Dokumentation ausgetauscht und entlang der gesamten Wertschöpfungskette genutzt werden können.
Technische Dokumentation als Basis für nachhaltige Entscheidungen • Grafik: plusmeta GmbH
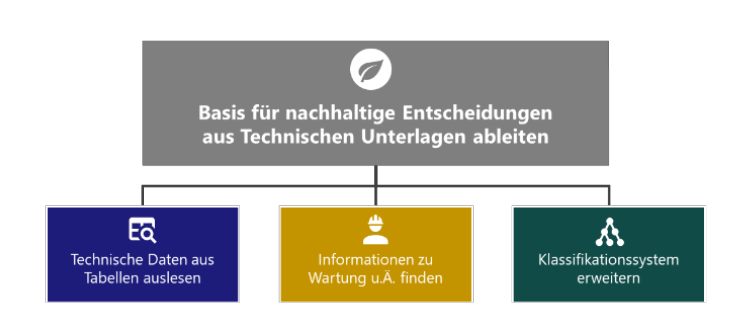
In diesem Blogbeitrag geben wir spannende Einblicke in den aktuellen Forschungsstand und teilen die wichtigsten Ergebnisse aus der ersten KREEN-Projektphase (Oktober 2023 bis März 2024).
Herausforderung: Tabellenverarbeitung mit KI
In technischen Dokumentationen wie Betriebs- oder Wartungsanleitungen sind entscheidende Informationen oft in Tabellenform strukturiert. Diese Tabellen sind für Menschen leicht lesbar, aber für KI-Anwendungen schwer zu verarbeiten, da diese nur den Textinhalt und nicht die Struktur einer Tabelle erfassen. Auch die große Vielfalt an Tabellenlayouts und komplexen Besonderheiten, wie verbundene oder geteilte Zellen, machen es der KI schwer, Tabellen sinnvoll zu interpretieren.
Wir nehmen uns dieser Herausforderung an und setzen uns das Ziel eine KI-Anwendung zu entwickeln, die Tabellen ähnlich wie ein Mensch interpretieren kann. Durch die gezielte Erkennung und Interpretation von Tabellen wollen wir die enthaltenen Informationen so aufbereiten, dass die Tabellenlogik für KI und maschinelle Verfahren erhalten bleibt. Das Ergebnis ist eine maschinenlesbare Tabelle.
Datenerfassung und -aufbereitung
Für die Entwicklung eines robusten Verfahrens zur Tabellenerkennung und -interpretation benötigen wir einen vielfältigen und repräsentativen Datensatz. Daher haben wir öffentliche technische Dokumente mit Tabellen in verschiedenen Größen, Formaten und von unterschiedlichen Herstellern gesammelt und einen entsprechenden Datensatz aus PDF-Dokumenten, die mindestens eine Tabelle enthalten und unterschiedlichen Dokumentarten und Herstellen angehöhren zusammengestellt und klassifiziert.
Zur Weiterverarbeitung wurden die Daten klassifiziert, z.B. mit der iiRDS-Dokumentart und der Dokumentsprache. Außerdem wurde erfasst auf welchen Seiten sich Tabellen befinden und welchen Komplexitätsgrad die Tabelle aufweist.
Eine repräsentative Teilmenge wurde für Tests, Modelltrainings oder Benchmarks ausgewählt.
Testdaten • Grafik: plusmeta GmbH

Technischer Überblick
Um Tabelleninhalte aus Dokumenten strukturiert zu extrahieren und für die weitere Verarbeitung nutzbar zu machen, durchläuft die KI-Anwendung mehrere aufeinanderfolgende Schritte. Diese umfassen die Identifikation und Interpretation der Tabellen, das strukturelle Erfassen von Tabelleninhalten sowie die Überführung der Daten in ein standardisiertes Ausgabeformat.
Teilschritte der Tabellenerkennung • Grafik: plusmeta GmbH, Viktoria Kurpas/Shutterstock.com
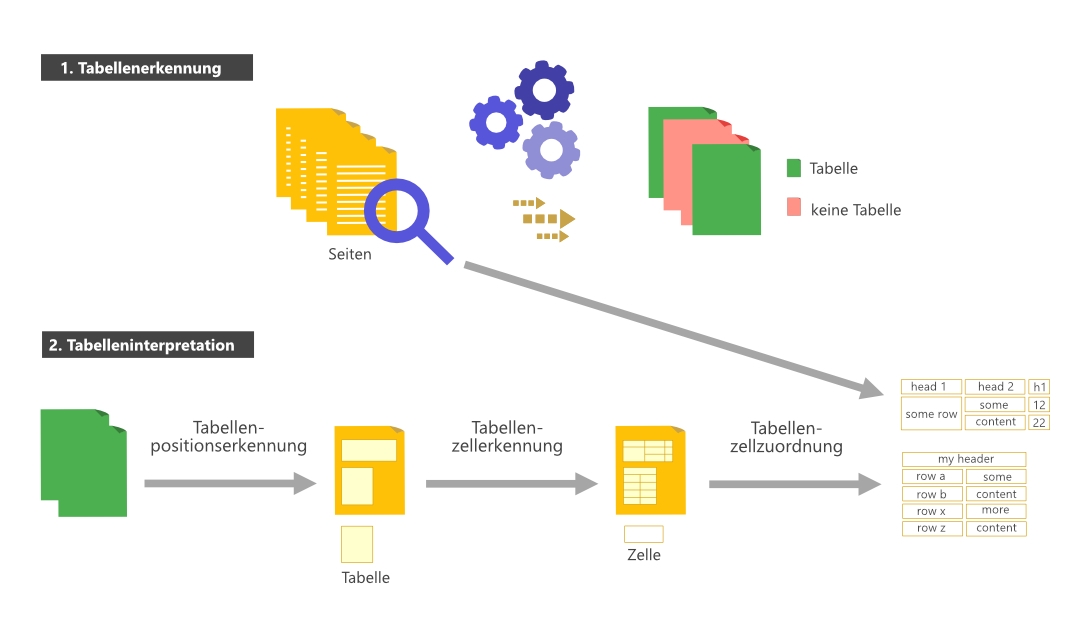
Tabellenerkennung
Im ersten Schritt werden die Seiten, die Tabellen enthalten identifiziert.
Tabelleninterpretation
Im zweiten Schritt wird die Position der Tabellen auf den jeweiligen Seiten identifiziert und anschließend die Position der einzelnen Tabellenzellen bestimmt. Als nächstes wird der Text in der Tabelle extrahiert und basierend auf der Zellpositionen in der Tabelle in ein strukturiertes Format gebracht. Output sind dann die entsprechenden Tabelleninhalte in strukturiertem Ausgabeformat.
Ausgabeformat und Zwischenformat
Für das endgültige Zielformat soll die angestrebte KI-Anwendung die eingegebenen Daten verarbeiten und ein standardisiertes Dateiformat erzeugen. Ein solches Format ist entscheidend, um die gewonnenen Daten effektiv in verschiedenen Softwaresystemen nutzen zu können. Aus den Anforderungen, die wir beim Austausch mit unseren Kunden gesammelt haben, ging AASX als gängigstes und gefragtestes Format hervor, einem Standard zur Verwaltung und Nutzung von Asset-Daten in Industrie-4.0-Umgebungen. So gewährleisten wir, dass unsere intelligenten Informationen nahtlos in Industrie-4.0-Systeme integriert werden können.
Bevor das endgültige Zielformat der KI-Anwendung Anwendung findet, wird allerdings ein Zwischenformat benötigt. Dieses Zwischenformat bildet das Verbindungsstück zwischen dem Output des Deep-Learning-Modells und der Weiterverarbeitung in plusmeta. In der zweiten Hälfte des Projekts soll zu diesem Thema eine Einigung erzielt werden.
Methodik - Recherche und Modellauswahl
Zu Testzwecken haben wir als erstes ein KI-Modell mithilfe des plusmeta-Workflows “KI-Modell trainieren” trainiert, um herauszufinden, ob wir ein eigenes Modell trainieren können oder ob wir auf einem vortrainierten Modell aufbauen müssen. Ergebnis dieses Tests ist, dass unsere aktuellen Methoden hier an ihre Grenzen stoßen. Die Performance des erstellten Modells ist auf realen Daten nicht zuverlässig genug, da nur der Textinhalt einer Seite ausgewertet wird, während optische Faktoren unberücksichtigt bleiben und Tabellen nur identifiziert, nicht aber interpretiert werden können.
Nach dieser ersten Testphase mit dem plusmeta-Workflow haben wir verschiedene Deep-Learning-Modelle evaluiert und uns für das Modell Multi-Type-TD-TSR (MTTT) entscheiden das sowohl Tabellenidentifikation als auch -interpretation durchführen kann.
Zur Halbzeit des Projekts ist ein erster Prototyp entstanden, der bereits Tabellen auf PDF-Seiten erkennt und deren Inhalte strukturiert extrahiert – ein entscheidender Schritt zur Integration in den plusmeta-Workflow.
Ausblick
In der ersten Projektphase konnten wir einen Großteil der konzeptionellen Arbeit erfolgreich abschließen und können uns nun in der zweiten Projekthälfte auf die Implementierung der KI-Anwendung fokussieren. Dabei geht es vor allem um das Erstellen eines neuen Workflows in plusmeta und die Integration in die bestehende IT-Infrastruktur der plusmeta Plattform.
Sie sind neugierig geworden?
Haben Sie es in Ihren Projekten auch mit Tabellen zu tun, die wichtige Informationen enthalten und effizient maschinell ausgelesen werden sollten? Oder würden Sie gerne ausführlicher von den Ergebnissen unseres Forschungsprojekts erfahren? Dann schreiben Sie uns gerne eine E-Mail an hallo@plusmeta.de!
Wenn Sie mehr über den Forschungsgegenstand und die Hintergründe des Projekts erfahren wollen, lesen Sie unseren Blogbeitrag zum Projektstart Blogbeitrag zum Projektstart.