

Der Schlüssel zur effektiven Nutzung von GenAI und LLMs: Metadaten


von Fabienne Rothenberg
Aug. 27, 2024


Retrieval Augmented Generation • Grafik: plusmeta GmbH, Viktoria Kurpas/Shutterstock.com
Mit der zunehmenden Verbreitung generativer KI-Technologien (GenAI) und Large Language Models (LLMs) wie OpenAI’s GPT und Meta’s LLaMA-Familie stehen Unternehmen heute mächtige Werkzeuge zur Verfügung, um umfangreiche und komplexe Dokumentationen effizienter zu verwalten. Doch trotz des immensen Potenzials dieser Technologien gibt es einige Herausforderungen, die es für den sicheren und effektiven Einsatz in der Technischen Dokumentation zu meistern gilt.
In diesem Blogbeitrag beleuchten wir diese Herausforderungen und stellen die „Retrieval Augmented Generation“-Technologie (RAG) vor, die durch den geschickten Einsatz von Metadaten eine vielversprechende Lösung bietet.
Die Herausforderungen beim Einsatz von LLMs
In der Technischen Dokumentation sind Präzision und Verlässlichkeit essenziell. Unmodifizierte LLMs stoßen dabei jedoch auf mehrere Herausforderungen:
1. Integration von Unternehmenswissen
Eine zentrale Herausforderung besteht darin, dass LLMs zwar auf riesigen Datenmengen trainiert wurden, aber kein spezifisches Unternehmenswissen enthalten, da dieses in der Regel nicht öffentlich zugänglich ist. Ein LLM kann also nicht einfach so Fragen zur Bedienung oder Instandhaltung firmenspezifischer Maschinen beantworten. Dieses Wissen muss das LLM zunächst erwerben. Allerdings erfordert das Nachtrainieren eines LLMs oft mehr Daten, als in einem Unternehmen verfügbar sind. Gleichzeitig sollten die Antworten eines LLM-basierten Chatbots ausschließlich auf unternehmensinternem Wissen basieren und nicht aus dem allgemeinen Trainingsdaten-Pool des LLM stammen.
2. Korrektheit der Ergebnisse
LLMs neigen dazu, „Halluzinationen“ zu erzeugen. Als Halluzinationen bezeichnet man Antworten, die zwar semantisch stimmig wirken, inhaltlich jedoch falsch sind. In der Technischen Dokumentation, wo genaue Informationen entscheidend für die Sicherheit und den Betrieb von Maschinen sind, können solche „erfundenen“ Antworten schwerwiegende Folgen haben. Diese Halluzinationen treten besonders dann auf, wenn das LLM keine präzisen Informationen zur Fragestellung findet.
3. Nachvollziehbarkeit der Informationsquellen
Die meisten LLMs funktionieren als „Black Boxes“, deren Entscheidungen auf komplexen neuronalen Netzwerken und Milliarden von Parametern basieren. Die genaue Quelle der Informationen, auf denen eine Antwort beruht, ist oft nicht transparent. Wenn ein LLM-basierter Chatbot jedoch sichere und verlässliche Informationen zum Betrieb einer Maschine liefern soll, ist es entscheidend, dass die Quelle der Antwort klar nachvollziehbar ist – besonders angesichts der zuvor erwähnten Neigung zu Halluzinationen.
4. Genauigkeit der Antworten
Da LLMs auf statischen Trainingsdaten basieren, können ihre Antworten veraltet oder unscharf sein, insbesondere wenn spezialisiertes Fachwissen gefragt ist. LLMs haben oft Schwierigkeiten, zwischen ähnlichen Produktvarianten zu unterscheiden, was in der Technischen Dokumentation von großer Bedeutung ist, da hier kleinste Details entscheidend sein können. Technische Dokumente enthalten häufig hohe Redundanzen – beispielsweise sind Bedienungsanleitungen zweier Produktvarianten textlich oft zu einem hohen Grad identisch, unterscheiden sich aber in wesentlichen Details wie technischen Daten oder speziellen Features. Diese Unterschiede werden in LLM-Szenarien oft übersehen. Wenn ein LLM bei der Anfrage nach einer Reparaturanleitung für den Ventilator „T3-B“ versehentlich die Anleitung für „T3-H1“ liefert, kann dies gravierende Folgen haben, etwa durch den Einsatz falscher Ersatzteile oder Werkzeuge.
Fach- und Domainwissen fehlt in der Regel in Standard-LLMs • Grafik: plusmeta GmbH, Viktoria Kurpas/Shutterstock.com

Diese Herausforderungen machen deutlich: LLMs können nicht ohne Weiteres auf Inhalte aus der Technischen Dokumentation angewendet werden. Doch es gibt Lösungen: Mithilfe der sogenannten RAG-Architektur lässt sich das allgemeine sprachliche Wissen der LLMs auf das spezifische Unternehmenswissen anwenden und darauf einschränken. Metadaten sorgen dafür, dass die Dokumente klar strukturiert und dem LLM verständlich zur Verfügung stehen, sodass präzise, nachvollziehbare und korrekte Ergebnisse gewährleistet werden können – insbesondere bei Dokumenten mit hohen Redundanzen, wie sie in der Technischen Dokumentation häufig vorkommen.
Wie das funktioniert, erklären wir im Folgenden:
Retrieval Augment Generation – So funktioniert RAG
Die RAG-Technologie bietet eine leistungsfähige Lösung für die genannten Herausforderungen, indem sie LLMs mit gezielt abgerufenen, relevanten Daten anreichert. Sie besteht vereinfacht dargestellt aus drei zentralen Komponenten:
1. Informationsbereitstellung durch vorgegebene externe Quellen („Retrieval“)
Bei der RAG-Architektur werden relevante, externe Datenquellen gezielt durchsucht, um dem LLM den für die Benutzeranfrage passenden Kontext zu liefern. Das können Textdokumente, strukturierten Datenbanken, Wissensgraphen und vieles mehr sein. Diese aus LLM-perspektive “externe Datenquelle” liefert das unternehmens- und produktspezifische Spezialwisssen. Techniken wie die Vektor-Suche ermöglichen es, die relevantesten Dokumente oder Daten zu identifizieren, die dann in den Prompt, also die Anfrage an das LLM, eingebunden werden.
2. Anreicherung des Prompts mit den Informationen der Quelle als Kontext („Augmentation“)
Die abgerufenen Informationen werden als zusätzlicher Kontext verwendet, um den Eingabeprompt des LLMs anzureichern. Dabei werden die Informationen so aufbereitet, dass sie nahtlos in den bestehenden Prompt integriert werden können. Dies ermöglicht es dem LLM, auf eine breitere Wissensbasis zurückzugreifen und somit fundiertere und präzisere Antworten zu generieren.
3. Generierung der Antwort durch das LLM („Generation“)
Durch die Verwendung des erweiterten Kontexts kann das Modell die Benutzeranfrage besser verstehen und relevantere Ergebnisse liefern. Das LLM nutzt sein breites, allgemeines Wissen über Sprache, um die gefundenen Datenfragmenten in eine wohlgeformte, natürlichsprachliche Antwort zu transformieren. Die Antworten sind nicht nur genauer, sondern basieren auch auf klar nachvollziehbaren Datenquellen, die bei Bedarf überprüft werden können.
Aufbau und Funktionsweise der RAG-Architektur • Grafik: plusmeta GmbH, Viktoria Kurpas/Shutterstock.com
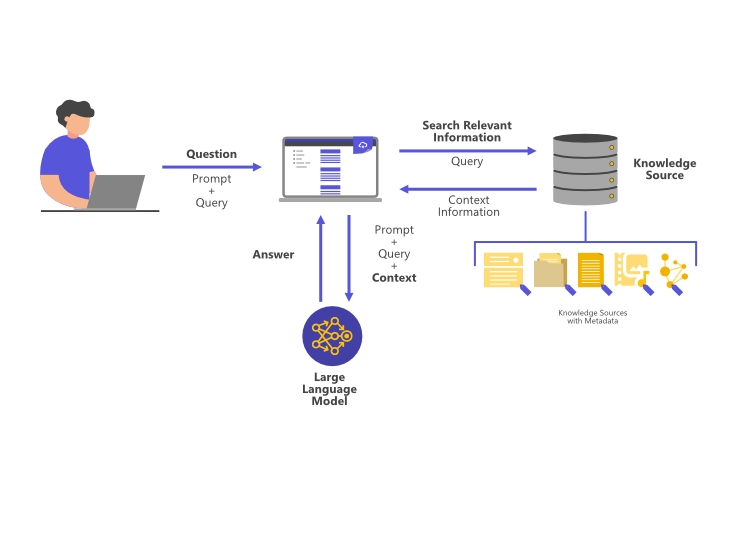
Die Vorteile von RAG-erweiterten LLM-Chatbots sind enorm. So lassen sich schnelle, valide Antworten in menschlicher Sprache bereitstellen und die Interaktion von Anwendern und Technikern mit dem gesamten Unternehmens- und Produktwissen auf ein nie dagewesenes Interaktions-Level heben. Die RAG-Architektur schließt dabei eine Lücke zwischen dem begrenzten Prompt-Umfang (Prompt Engineering), der einem Sprachmodell zur Beantwortung mitgegeben werden kann und dem aufwändigen, zeit- und ressourcenintensiven Nachtrainieren des gesamten Sprachmodells (Fine-Tuning).
So bietet die RAG-Architektur eine praktikable Lösung, wie LLMs mit den eigenen unternehmensspezifischen Informationen erweitert werden können. Doch um das volle Potenzial dieser Technologie ausschöpfen zu können, müssen einige entscheidende Vorarbeiten geleistet werden. So genügt es nicht, den gesamten Datenschatz einfach in unstrukturierter Form in das System zu „schütten“.
Für valide und hochwertige Ergebnisse bedarf es einer aufbereiteten und strukturierten Wissensbasis, welche dem LLM als fundierte Informationsquelle dient – und hier spielen Metadaten eine Schlüsselrolle.
So leicht geht es leider nicht. Für den Einsatz in der RAG-Architektur muss Wissen zunächst aufbereitet und strukturiert werden. • Quelle: plusmeta

Die entscheidende Rolle von Metadaten
Metadaten sind Daten, die Informationen über andere Daten enthalten, wie etwa Dokumenttitel, Produktbezug des Dokuments, Seriennummern oder technische Spezifikationen. Sie strukturieren und organisieren große Datenmengen und ermöglichen es LLMs, die richtigen Informationen schnell und präzise zu finden. In einer RAG-Architektur sorgen Metadaten dafür, dass der richtige Kontext für die Generierung von Antworten bereitgestellt wird – besonders wichtig in der Technischen Dokumentation, wo ähnliche Inhalte oft fein nuanciert sind.
Durch die Verwendung von Knowledge Graphen können Metadaten in Beziehung gesetzt und Informationen intelligent strukturiert werden. Eine sorgfältige Pflege und Verwaltung von Metadaten bildet somit die Grundlage für präzise, aktuelle und kontextbezogene Antworten, die für den sicheren und effektiven Einsatz von LLMs in der Technischen Dokumentation unerlässlich sind.
Nehmen wir uns das Beispiel von oben aus Herausforderung 4: Die beiden Reparaturanleitungen von den sich ähnlichen Produkten T3-B und T3-H1 haben einen hohen Anteil an redundanten Informationen. Dass der relevante Unterschied zwischen den Dokumenten der Bezug auf die Produktvariante T3-B bzw. T3-H1 ist, ist Wissen, dass das LLM nicht hat. Durch die Anreicherung der Reparaturanleitungen mit Metadaten, werden die Dokumente klar im Wissensraum eingeordnet und spezifiziert: Sowohl was es für eine Information ist (Reparaturanleitung) als auch für welches Produkt (T3-B bzw. T3-H1) ist nun als wesentliche Information für das LLM vorhanden.
Werden in einem Knowledge Graph zudem die Metadaten miteinander in Verbindung gebracht, entsteht zusätzliches Wissen, das in den LLM-Prompt aufgenommen werden kann. Wie etwa das Wissen, dass T3-B für die Basisausführung des Tischventilators mit 3-Geschwindigkeitsstufen steht. Im Knowledge Graph ist das Wissen in performant maschinell durchsuchbarer Art und Weise gespeichert.
Fragt nun ein Anwender nach Bedieninformationen seines Tischventilators in Basisausführung, kann das LLM die Produktvariante T3-B identifizieren und passenden Content, der mit diesem Metadatum ausgezeichnet ist, auffinden.
plusmeta – Der Enabler für GenAI in der Technischen Dokumentation
Das Potenzial von GenAI und LLMs für die Technische Dokumentation ist enorm und wird in Zukunft weitere spannende Anwendungsfälle eröffnen. Doch dieses Potenzial lässt sich nur ausschöpfen, wenn die zugrunde liegenden Informationsquellen umfassend strukturiert und mit Metadaten versehen sind. Das ist die perfekte Grundlage für Technologien wie RAG, die die Anwendung von LLMs auf Unternehmenswissen ermöglichen.
Die plusmeta-Plattform bietet ein umfassendes Set intuitiver Workflows für die automatisierte Metadatenvergabe und die Aufbereitung von Bestandsdokumenten. Dadurch entsteht die notwendige Basis für den sicheren und effektiven Einsatz von RAG- und GenAI-Technologien.
Sie möchten mehr über die vielfältigen Möglichkeiten erfahren, wie Sie plusmeta bei der Aufbereitung Ihres Contents unterstützen kann? Dann nehmen Sie noch heute Kontakt zu uns auf und vereinbaren einen unverbindlichen Demotermin mit uns. Gerne stellen wir Ihnen plusmeta und die vielfältigen Einsatzmöglichkeiten persönlich vor.