

iiRDS in Theorie und Praxis. Teil 2 - iiRDS-Pakete mit KI-Unterstützung


von Eva-Maria Wolf
Aug. 12, 2021


iiRDS mit KI-Unterstützung einfach erstellt • Grafik: plusmeta GmbH, Viktoria Kurpas/Shutterstock.com
Der Standard iiRDS erleichtert den Austausch von Metadaten zwischen verarbeitenden Systemen, wie zum Beispiel einem Redaktionssystem und einem Content-Delivery-Portal. Doch was passiert, wenn iiRDS auf die mit Leben gefüllte PI-Klassifikation eines Redaktionssystems trifft?
Nachdem Mark Schubert im ersten Teil der Blogserie iiRDS in Theorie und Praxis gezeigt hat, wie man die PI-Klassifikation und iiRDS mit OWL-Mappings zusammenführt, erfahren Sie im zweiten Teil der Serie, wie Sie KI-basierte Software dabei unterstützt, CMS-Inhalte in konforme iiRDS-Pakete zu packen. Denn in der Regel müssen große Bestandsdatenberge bearbeitet werden, wenn moderne Anwendungen für alle Produktvarianten ausgerollt und nicht als einsame Leuchttürme für Beispieldaten stehen bleiben sollen.
plusmeta – Metadaten automatisch
Haben Sie schon einmal mit dem iiRDS-Open Toolkit gearbeitet? Wenn ja, dann kennen Sie bereits den „kleinen Bruder“ von plusmeta. Wie in plusmeta können Sie mit dem iiRDS-Open-Toolkit manuelle iiRDS-Metadaten vergeben und iiRDS-Pakete generieren. In plusmeta unterstützt Sie zusätzlich unsere eigenentwickelte Künstliche Intelligenz (KI) bei der Vergabe der Metadaten. Teilweise kann diese die Aufgabe sogar komplett für Sie übernehmen. Sie prüfen die Ergebnisse anschließend nur noch.
plusmeta ist eine webbasierte Software, die mithilfe von KI semantische Metadaten an Produktinformationen vergibt. Unsere KI ist auf die Inhalte der Technischen Kommunikation spezialisiert. Die KI ersetzt die Arbeit von Technischen Redakteur:innen dabei nicht, sondern unterstützt, schnell und zielsicher die passenden Werte zu setzen. Laut den Erhebungen unserer Kunden sind mit plusmeta Aufwandseinsparungen von bis zu 80 % erreichbar.
In 4 Schritten zu iiRDS-konformen Metadaten
Damit Sie die Pakete im Produktivbetrieb wie von Zauberhand generieren können, sind wenige Konfigurationsschritte notwendig.
Ganz ähnlich wie im ersten Blogartikel dieser Serie beschrieben, werden auch in plusmeta die vorhandenen Metadaten eingelesen und auf die iiRDS-Konzepte gemappt. Zusätzlich erkennt die KI weitere relevante Metadaten. Das Ergebnis wird nach einer Prüfung durch Redakteur:innen automatisch als iiRDS-Paket gespeichert.
In den folgenden Abschnitten wird jeder dieser Schritte im Detail erläutert.
 In vier Schritten von CMS-Inhalten mit PI-Klassifikationen zu iiRDS-Paketen. • Grafik: plusmeta GmbH
In vier Schritten von CMS-Inhalten mit PI-Klassifikationen zu iiRDS-Paketen. • Grafik: plusmeta GmbH
Schritt 1: Importieren - Content aus dem CMS
Um die Inhalte mit allen nutzbaren Informationen aus dem CMS zu ziehen, nutzen wir bei plusmeta am liebsten HTML. Denn ein HTML-Export liefert bereits alle Informationen für die Darstellung in den späteren Zielsystemen (z.B. Content-Delivery-Portal). Des Weiteren kann über eine Navigationsseite (index.html) der Zusammenhang zwischen den Informationsbausteinen mitgeliefert werden.
Entscheidend ist, dass der HTML-Export die im CMS vergebenen Metadaten enthält - im Idealfall inklusive eindeutiger Identifikatoren und Angaben zur Klasse. Je nach eingesetztem CMS können Sie den HTML-Export und die darin enthaltenen Daten selbst konfigurieren, z.B. bei Schema ST4 über eine entsprechende OMD-Produktion. Bei Cosima von Docufy sind die Metadaten im DYXML enthalten, wenn man das aktuelle Layout-Paket verwendet.
Namen sind dabei nur Schall und Rauch, denn Benennungen bzw. Labels können sich ändern. Um eine stabile, sicherere Verbindung zu schaffen, setzen wir in der Regel auf Identifikatoren und IDs. Indem wird beispielsweise die von iiRDS vorgegebenen URI (Unique Ressource Identifier) für die iiRDS-Klassen und -Beziehungen verwenden, ist sichergestellt, dass auch über Systemgrenzen hinweg „dasselbe Ding“ aus iiRDS eineindeutig gemeint ist.
Die Art und Weise, wie man Metadaten aus den CMS bekommt, kann sehr unterschiedlich ausfallen. Das folgende konstruierte Beispiel zeigt einige der Varianten in einer Datei. Die Metadaten befinden sich in der HTML-Datei im <head> in den <meta ...>-Tags:
Beispiel-HTML-Export • Grafik: plusmeta GmbH
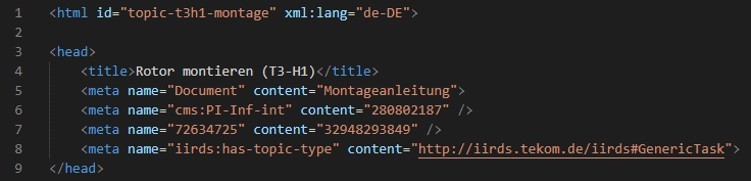
Das Attriubut „name“ enthält die Angaben zu Klassen bzw. zur Beziehung, über die ein Wert vergeben wird. Im Attribut „content“ steht der Metadatenwert.
Die Tabelle zeigt empfehlenswerte Vorgehensweisen für die unterschiedlichen Exportformen, in denen Metadaten in den HTML-Exporten vorkommen können.
Zeile | HTML | Vorgehen |
5 | Label von Klasse und Wert | Alle Klassen und Werte mit Identifikatoren in plusmeta anlegen und über die Labels mappen. |
6 | Klasse mit Identifikator und Wert als ID | Identifikatoren der Klasse in plusmeta übernehmen. Für sprechende Labels in plusmeta ist eine weitere Datei notwendig, welche die Labels zu den IDs enthält. |
7 | Klasse und Identifikator mit IDs | Eine weitere Datei ist notwendig, die zu den IDs der Klassen und Werte die passenden Labels enthält. |
8 | Im CMS gemappte iiRDS-Werte | Bei Werten, die schon im CMS eindeutig gemappt werden können, ist die einfachste Lösung, die iiRDS-Identifikator bereits im CMS zu hinterlegen und ins HTML zu schreiben. Wichtig ist dabei, die exakten iiRDS-Identifikatoren zu verwenden. |
Enthält der Export systemspezifische IDs, z.B. die CMS-ID der Metadaten (Zeile 7 im Beispiel), werden diese idealerweise auch in plusmeta hinterlegt. Dadurch sind beliebige Durchläufe aus Im- und Export möglich. Die Systeme erkennen die Metadaten wieder. Dieselben Werte werden nicht mehrfach, ohne Verbindung neu angelegt.
Die bevorzugte Variante ist aus plusmeta-Sicht die in Zeile 6 gezeigte Variante. Die Klasse und die vergebenen Werte sind eindeutig anhand der URI und der ID identifizierbar. Zugehörige Labels können über einen Eigenschaftenimport leicht hinzugefügt werden.
Schritt 2: Mappen – Was nicht passt, wird passend gemacht!
Ist der Import der CMS-Metadaten vorbereitet, kommt als nächster Schritt die Definition von Mappings. Ganz ähnlich wie im ersten Blogartikel der Serie von Mark Schubert beschrieben, werden auch in plusmeta Mappings definiert, um die tief verschachtelten PI-Taxonomien (PI-Class®) auf die passenden iiRDS-Konzepte abzubilden.
 Beispiel-Mapping für einen Informationsbaustein mit zwei PI-Klassifikationen • Grafik: plusmeta GmbH
Beispiel-Mapping für einen Informationsbaustein mit zwei PI-Klassifikationen • Grafik: plusmeta GmbH
plusmeta setzt wie iiRDS auf das Konzept Metadatenwerte über Beziehungen zu vergeben. Das hat den Vorteil, dass auch die Beziehung klassifiziert werden kann. Beispielweise kann die Klasse „Dokumentart“ sowohl eine Beziehung „hat Dokumentart“ (für Dokumente) als auch eine Beziehung „ist geeignet für Dokumentart“ (für Topics) haben.
Beim Modellieren der Beziehungen unterstützt Sie plusmeta z.B. durch die Darstellung der Beziehungen in einem Knowledge Graph. So können Sie beispielsweise angeben, dass bei einem Input „Informationsbezogen intrinsisch = Aufbau“, die folgenden iiRDS-Beziehungen für die entsprechende Information Unit gezogen werden:
- has topic type = Reference (generic)
- has subject = Overview control element
Das Prinzip von iiRDS ausschließlich Werte und keine Klassen bei der Vergabe zuzulassen ist in plusmeta ebenfalls das präferierte Vorgehen. Für unternehmensspezifisch erweiterte Werte (dunkelblauer Wert „Operator“ in der Grafik) ist es empfehlenswert, sich ein Konzept für die Identifikatoren zu überlegen. Unternehmensspezifische Namensräume und URIs können genutzt werden. Alternativ kann plusmeta global eindeutige IDs (UUID) als Identifikatoren erzeugen. Diese sollten dann entsprechend auch angrenzenden Systemen übernommen werden.
Schritt 3: Erweitern – Eine Frage der Perspektive
In vielen Fällen ist die Arbeit allein mit dem Mappen nicht getan: die im CMS gepflegten Metadaten reichen oft nicht aus. Der Fokus der in CMS gepflegten Metadaten liegt in der Regel auf der Erstellung der Technische Dokumentationen. Das heißt die Inhalte sind mit Metadaten ausgezeichnet, die bei der Aggregation von Dokumenten oder der Filterung für spezifische Produktvarianten helfen. Beispiele dafür sind Gültigkeiten wie Produktvarianten-Nummern oder variantenkennzeichnende Merkmale. Für die anwendungsorientierte Navigation durch modulare Inhalte in Content-Delivery-Portalen sind dagegen Metadaten aus Anwender:innen-Perspektive wichtig, z. B. die einzelnen Bestandteile, Funktionen oder die Merkmale der Produkte.
Wurden diese trotz PI-Klassifikationsmodell vergessen oder nachlässig gepflegt, weil sie bisher keine Auswirkung hatten, können die Informationen in plusmeta leicht von der KI verifiziert oder ergänzt werden. Die intrinsischen Merkmale sind sogar das Spezialgebiet unserer KI, denn um was es in den Informationsbausteinen geht, lässt sich aus den Texten sehr gut ableiten. Unsere KI-Werkzeugkoffer bringt dafür folgende Tools mit:
Methode | Anwendungsfälle |
Knowledge Graph Vergabe über definierte Beziehungen zwischen Metadaten. | Werte, die über Beziehungen abgeleitet werden können:
|
Regelbasierte Erkennung Vergabe auf Basis von Regeln zu im Text gefundenen Indikatoren. | Werte, die im Text direkt oder als Synonyme auffindbar sind:
|
Extraktoren Werte-Extraktion anhand definierter Muster. | Werte, die spezifischen Mustern folgend und nicht als Werteliste vorgehalten werden sollen:
|
Machine Learning Vorhersage der Metadaten mithilfe eines trainierten KI-Modells. | Werte, die nicht direkt aus dem Text ablesbar sind, aber anhand komplexer, durch die KI identifizierter Muster zuweisbar sind:
|
Die Methoden können über Fallback-Mechanismen kombiniert werden, sodass z. B. die Regelbasierte Erkennung einen Wert liefern kann, wenn kein mapping-fähiger Wert im Input enthalten war.
Mut zur Lücke
iiRDS bringt ein umfangreiches Vokabular mit. Das heißt aber nicht, dass alle vorhanden Klassen und Werte an allen Objekten genutzt werden müssen. Welche Metadaten gesetzt werden sollen, legt iiRDS nicht fest.
In manchen Fällen gilt auch die Maxime „Mut zur Lücke“. So sind die iiRDS-Klassen Produktlebenszyklusphase und Informationsthema beinahe komplementär zueinander. Wenn ein Wert aus einer der beiden Klassen vergeben ist, ist schon das Wichtigste klar.
Letztendlich entscheiden Sie, welche Metadaten Sie für Ihre Anwendungen brauchen. Wir empfehlen den Gesamtprozess zu analysieren und zu prüfen, welche Metadaten wo benötigt werden und auf dieser Basis zu entscheiden, welche Metadaten vergeben werden sollen.
Schritt 4: Ausgeben – Alles gut verpackt
Der letzte Schritt ist die Ausgabe der Inhalte und erkannten Metadaten als iiRDS-Pakete. Hier ist von Redakteur:innen-Seite keinerlei Eingreifen nötig. plusmeta hat alle Anforderungen des Standards implementiert und kümmert sich auch darum, dass iiRDS-spezifische Besonderheiten eingehalten werden. Dazu zählen beispielsweise die folgenden Punkte:
- Die Herstellerbeziehung wird zur Produktvariante oder Komponente gezogen, nicht direkt zum Paket.
- Die Content Lifecycle Status wird für die Information Units angegeben.
- plusmeta leitet den hierarchischen Zusammenhang der Informationsbausteine, wenn vorhanden, aus der index.html ab und übernimmt sie iiRDS-konform als Directory node.
plusmeta paketiert die Inhalte und erstellt alle vom Standard geforderten Dateien und Strukturen automatisch. So werden alle gesetzten Metadaten, Objektreferenzen und ihre entsprechenden Beziehungen in einer rdf-Datei ausgegeben. Die Dokumente und Topics werden in die vorgesehene Ordnerstruktur eingegliedert und ein zip-Paket erstellt. Das Paket erhält die Datei-Endung „.iirds“.
Workflow-basiert zum iiRDS-Paket
Ist plusmeta einmal wie oben beschrieben eingerichtet, können Redakteur:innen im Handumdrehen iiRDS-Pakete aus CMS-Inhalten erstellen.
Bestehende Metadaten werden übernommen und auf iiRDS-Metadatenkonzepte gemappt. Fehlende Metadaten werden von der KI ergänzt. Nachdem die Metadaten von Redakteur:innen geprüft wurden, entsteht das iiRDS-Paket auf Knopfdruck und kann an unterschiedlichste iiRDS-Konsumenten verteilt werden.
 Workflow zum Erstellen von iiRDS-Paketen • Grafik: plusmeta GmbH
Workflow zum Erstellen von iiRDS-Paketen • Grafik: plusmeta GmbH
Fazit
Mit plusmeta können CMS-Inhalte und deren Metadaten leicht in das Standardaustauschformat iiRDS gebracht werden. Die Software unterstützt beim Mapping der Konzepte, bei der Erstellung der Pakete. Mithilfe der KI können die Inhalte mit weiteren fürs Content Delivery notwendigen Metadaten angereichert werden.
Dieser Blogartikel zeigt, wie wir typischerweise in der Praxis in unseren Kundenprojekten von PI klassifizierten CMS-Inhalten zu iiRDS-konformen Paketen kommen. Das Vorgehen und die dabei zu überwindenden Herausforderungen sind am Beispiel der Konfiguration der KI-basierten Software plusmeta dargestellt. Einige der beschriebenen Schritte und teilweise auch die Lösungen sind auf anderen Vorgehensweisen ohne eine entsprechende Softwareunterstützung übertragbar.
Sie wollen mehr über plusmeta erfahren oder haben noch eine Frage? Dann schreiben Sie uns eine Mail an hallo@plusmeta.de oder besuchen Sie unsere Website.