

Interview: Künstliche Intelligenz in der Technischen Dokumentation, Teil 1


von Mischa Vollmann
Jan. 04, 2022


Künstliche Intelligenz und Technische Dokumentation Hand in Hand • Grafik: plusmeta GmbH
Schon heutzutage ist Künstliche Intelligenz in der Technischen Dokumentation](/software/) verbreitet. Zum Beispiel dann, wenn es um die Vergabe von Metadaten geht. Aber was hat es mit Künstlicher Intelligenz genau auf sich und welche Methoden werden in Technischen Redaktionen schon eingesetzt? Diese Fragen haben Fabienne Rothenberg und Eva-Maria Meier in einem Interview mit Susanne Meier von Quanos Content Solutions im Rahmen der tekom-Jahrestagung beantwortet.
Interview Teil 1: Künstliche Intelligenz und Technische Dokumentation
Frau Lange, Frau Wolf, der Begriff „Künstliche Intelligenz“ ist in aller Munde. Können Sie uns erklären, was es mit Künstlicher Intelligenz genau auf sich hat und ob das mehr ist als nur ein momentaner Trend?
Eva-Maria Wolf: Künstliche Intelligenz (KI) ist ein Teilgebiet der Informatik, das versucht menschliches Denken und Handeln zu imitieren. Den Begriff klar zu definieren ist schwierig, da die Grenzen zwischen KI und komplexen Algorithmen schwimmend sind. Wir verfolgen ein pragmatisches Verständnis von Künstlicher Intelligenz. Das bedeutet, wir nehmen an, dass es sich um Künstliche Intelligenz handelt „wenn das Ergebnis, das eine Software liefert, intelligent wirkt“.
Das Forschungsfeld gibt es schon sehr lange. Einige Methoden wurden bereits in den frühen 80er-Jahren entwickelt. In den letzten Jahren bekommt das Thema Aufschwung, weil durch größere Rechnerleistung und Cloud-Architekturen mehr Leistung für wenig Geld verfügbar ist. Dadurch können komplexe Modelle verarbeitet werden und Fortschritte erzielt werden.
In der Technischen Kommunikation ist Künstliche Intelligenz seit ca. 2 Jahren ein echtes Trendthema. Das liegt wahrscheinlich auch daran, dass immer mehr Softwareprodukte auf KI setzen.
Würden Sie sagen, dass die Menschen grundsätzlich offen für Künstliche Intelligenz sind oder begegnen sie dieser eher mit einer gewissen Skepsis?
Fabienne Rothenberg: Die meisten Menschen haben in ihrem Alltag bewusst oder unbewusst bereits Kontakt zu KI-Anwendungen. Beispiele dafür sind z.B. Empfehlungen in Streaming-Diensten, Sprachassistenten wie Alexa und Siri, Kontrollmechanismen in Social Media Plattformen, Mail-Spamfilter und Maschinelles Übersetzen.
Im Umfeld der Technischen Kommunikation ist das Thema noch nicht ganz so alltäglich. Hier erleben wir in unserem Arbeitsalltag in erster Linie großes Interesse und Neugier. Allerdings sind wir auch schon mit der Sorge konfrontiert worden, dass Technische Redakteur:innen durch KI-Anwendungen ersetzt werden könnten. Diese Gefahr sehen wir allerdings aus mehreren Gründen nicht. Trotzdem gibt es - wie bei jeder neuartigen Technologie - Menschen, die Künstlicher Intelligenz skeptisch gegenüberstehen.
Die Angst vor der KI, die die Weltherrschaft übernimmt, können wir aber nehmen: Die heutigen Formen Künstlicher Intelligenz können nur das tun, wofür sie erstellt und trainiert wurden. Dabei sollen sie immer eine Unterstützung sein. Ein Werkzeug, das Menschen hilft und aufwendige Arbeiten reduziert.
Es gibt ja unterschiedliche Arten von Künstlicher Intelligenz. Welche Arten gibt es denn, und was bewirken sie?
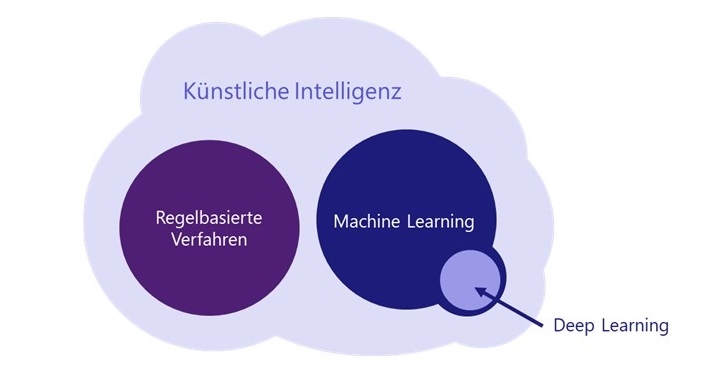
Eva-Maria Wolf: Welche Arten man unterscheidet, hängt von der Perspektive ab. Bei unserem pragmatischen KI-Verständnis unterscheidet man im Wesentlichen zwei Hauptfelder: Die regelbasierten Verfahren und das Machine Learning.
Bei den regelbasierten Verfahren werden Regeln zur Lösung von Problemstellungen programmiert nach dem Muster: Wenn Fall „x“ eintritt, tue „y“. Die Regeln sind kombinierbar und so können komplexe Systeme entstehen, die einen intelligent wirkenden Output liefern. Regelbasierte Verfahren umfassen auch Mustererkennung in Texten über Reguläre Ausdrücke und das Auswerten von Knowledge Graphen.
Anders als bei den regelbasierten Verfahren wird beim Machine Learning der Lösungsweg nicht vorgegeben. Hier lernt die KI aus statistischen Werten und Erfahrungen. Bei der Programmierung werden lediglich die Problemstellung und die Rahmenbedingungen sowie die Information, wie gelernt wird, mitgegeben. All diese Infos stecken in einem Modell. Vielleicht kommen wir darauf später noch einmal zu sprechen.
In den Medien ist in der Regel von Deep Learning die Rede, wenn es um Künstliche Intelligenz geht. Das ist ein Teilgebiet des Machine Learning. Hier werden komplexe Modelle mit vielen Schichten bestehend aus vielen vernetzen Entscheidungspunkten (Neuronen) aufgebaut. Im Prinzip versucht man dabei, das menschliche Gehirn nachzubauen, um komplexe Aufgabenstellungen wie Bilderkennung lösen zu können.
Damit die vielen Schichten gebildet werden können, sind sehr viele Trainingsdaten erforderlich. Hier haben beispielsweise Unternehmen wie Google mit allgemeinen Aufgabestellungen einen großen Vorteil, da sie z. B. alle Bilder aus ihren Online-Cloud-Lösungen zum Training einsetzen können.
Welche Kriterien die Künstliche Intelligenz zur Entscheidungsfindung heranzieht ist nicht einsehbar. Die Netze sind wie eine Blackbox.
Formen von Künstlicher Intelligenz • Grafik: plusmeta GmbH
Eine weitere Unterteilungsmöglichkeit für KI ist das „Format“ der zu verarbeitenden Daten. Dann unterscheidet man z. B. zwischen Bilderkennung sowie -klassifikation und Natural Language Processing. Beim Natural Language Processing geht es um das Verstehen und Generieren natürlicher Sprache.
Ein wichtiges Thema in der Technischen Dokumentation ist die Metadatenvergabe. Dort bringt Künstliche Intelligenz mittlerweile eine deutliche Arbeitserleichterung für die Technischen Redakteure. Können Sie erklären, wie die Metadatenvergabe mittels der sogenannten regelbasierten Verfahren funktioniert?
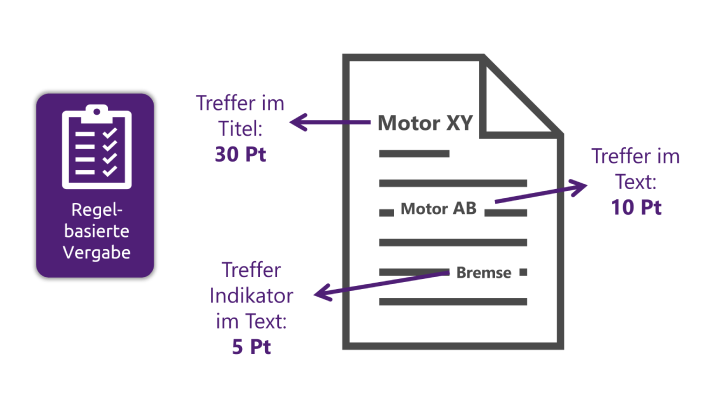
Fabienne Rothenberg: Simpel ausgedrückt wird bei den regelbasierten Verfahren anhand vordefinierter Regeln entschieden, welche Metadaten vergeben werden. In den meisten Fällen wird dabei ein Text mit einer vordefinierten Werteliste abgeglichen. Wenn also beispielsweise ein bestimmtes Wort in einem Text gefunden wird, das in der Werteliste vorhanden ist, dann könnte dieses Wort als Metadatum vergeben werden. Tatsächlich ist die regelbasierte Vergabe aber deutlich komplexer. Hier werden verschiedene Regeln mit Suchmustern kombiniert, die eine genaue Metadatenvorhersage ermöglichen.
So ist unter anderem relevant, wo im Text das Wort gefunden wurde, ob das Wort selbst oder ein Indikator (bspw. ein Synonym) gefunden wurde und ob es sich um einen exakten Treffer oder ein Fuzzy Match handelt. In den meisten Fällen gibt es dabei dann auch mehrere Treffer im Text und die KI entscheidet anhand weiterer Regeln, welcher Treffer am wahrscheinlichsten ist, oder ob sogar mehrere Treffer vorgeschlagen werden.
Funktionsprinzip der regelbasierten Vergabe • Grafik: plusmeta GmbH
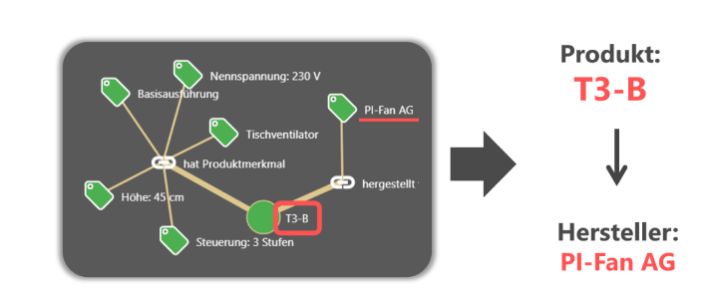
Zudem können mithilfe von Wissensnetzen Abhängigkeiten zwischen Metadaten definiert werden oder sogar ganze Produktmodelle als Metadatennetz angelegt werden. Auch diese Wissensnetze können dann regelbasiert ausgewertet werden: Wenn ein bestimmter Wert “A” als Metadatum vergeben wurde, dann vergib auch Wert “B”.
Ein einfaches Beispiel dafür sind die Metadaten „Produkt“ und „Hersteller“. Über ein kleines Produktmodell kann hier ausgedrückt werden, wer das Produkt hergestellt hat. Wird dann das Produkt (z.B. “T3-B”) im Text gefunden, kann auch der Hersteller (z.B. “PI-Fan AG”) als Metadatum mitvergeben werden.
Darstellung von Abhängigkeiten und Beziehungen zwischen Metadaten für die regelbasierte Erkennung • Grafik: plusmeta GmbH
Der große Vorteil dieser regelbasierten Verfahren ist es, dass kein aufwendiges Training erforderlich ist. Mithilfe eines bestimmten Standard-Regelsatzes können die meisten Metadaten vorhergesagt werden. Passt etwas nicht, kann man die Regeln ganz einfach justieren. Am besten funktioniert das bei allen Metadaten, die in irgendeiner Form aus dem Text herausgelesen werden können, wie beispielsweise Produktbezeichnungen, Seriennummern, Baugruppen und Tätigkeiten.
Auch Machine Learning kann bei der Metadatenvergabe unterstützen. Wie funktioniert das genau?
Eva-Maria Meier: Beim Machine Learning benötigen wir immer – wie eingangs schon erwähnt –ein Modell als Basis. Das Modell muss dabei genau für die zu lösende Aufgabe trainiert sein, z. B. zum Erkennen der Dokumentart von PDF-Dateien.
Bei plusmeta arbeiten wir für die Inhaltsklassifikation mit “Überwachtem Lernen”. Beim “Überwachten Lernen” füttern wird die Künstliche Intelligenz mit gelabelten Beispieldokumenten. Wir benötigen dabei für jeden Wert eine kritische Menge an Beispielen aus der die KI lernen kann die Werte zu unterscheiden.
Training eines ML-Modells • Grafik: plusmeta GmbH
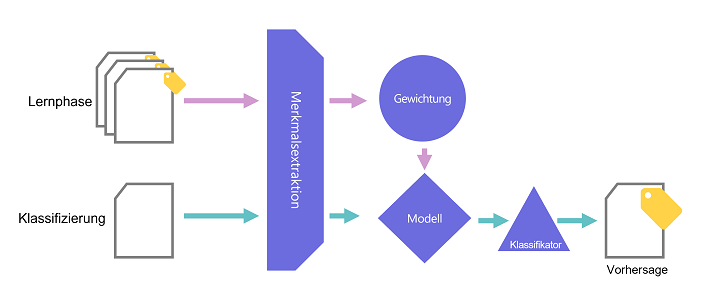
Die KI extrahiert dafür Merkmale. Diese werden gewichtet und fließen in das Modell ein. Welche Merkmale extrahiert werden, wird über einen Algorithmus bestimmt. Die Gewichtung ist dagegen eine veränderbare Stellschraube. Im Modell sind die charakteristischen Punkte für jeden Metadatenwert hinterlegt und in Form eines Vektors gespeichert.
Zeigen wir der KI anschließend unklassifizierte Texte, läuft dieselbe Merkmalsextraktion ab und die KI vergleicht, zu welcher Dokumentart die gefundenen Merkmale am besten passen. Liegt der Vektor des neuen Dokuments z. B. nahe am typischen „Bedienungsanleitungsvektor“, wird dieser Wert vorhergesagt. Die KI ist dabei immer nur so gut, wie das Modell aus dem Training. Es ist also besonders wichtig, die KI mit sehr gut klassifizierten Beispielen zu trainieren.
Trotzdem kann die KI auch mal falsch liegen. Im Feld erreichen wir bei sehr guten Modellen eine Genauigkeit von ca. 92%. Die Ergebnisse müssen daher immer noch einmal von Menschen geprüft werden. Liegt die KI falsch, kann ein Nachtraining mit der Korrektur angestoßen werden. Am besten arbeiten Künstliche Intelligenz und Technische Redakteur:innen also Hand in Hand!
Frau Wolf, Frau Lange, vielen Dank für diesen ersten Teil des Gesprächs!
Teil 2 des Interviews im Blog von Quanos!
Einsatzmöglichkeiten von Künstlicher Intelligenz, deren Chancen aber auch Grenzen - Das sind die Themen im zweiten Teil dieser Blogserie. Zu lesen im Blog von Quanos.
Du willst mehr über die Künstliche Intelligenz von plusmeta erfahren oder hast noch eine Frage? Dann schreib uns eine Mail an hallo@plusmeta.de oder besuche unsere Website.