

Was ist NLP?


von Eva-Maria Wolf
Feb. 16, 2023


Gehen Sie mit uns auf Tauchgang und erfahren Sie mehr über Natural Language Processing, Embeddings, Transfer Learning, Zero-Shot-Learning • Grafik: plusmeta GmbH, Viktoria Kurpas/Shutterstock.com
In unserem Forschungsprojekt DEEEP, das vom Wirtschaftsministerium Baden-Württemberg gefördert wird, erweitern wir plusmeta um eine Deep-Learning-Komponente. In unserer Blogserien tauchen wir mit Ihnen tiefer ein in die Themenfelder, die wir in unserem Forschungsprojekt bearbeiten. Heute erfahren Sie, wie KI Sprache versteht.
Natural Language Processing – Computer lernen sprechen
Das Gebiet der künstlichen Intelligenz, das sich mit dem Verstehen, Verarbeiten und Produzieren natürlicher Sprache beschäftigt, nennt sich Natural Language Processing (NLP). Eine weitere gängige Bezeichnung ist „Computer Linguistik“. In diesem KI-Anwendungsgebiet gibt es seit 2012 einen regelrechten Innovationsschub.
Grund dafür ist die Verfügbarkeit von mehr Rechenpower. Sie ermöglicht es, Modelle mit größeren Textmengen zu trainieren. Die Menge der nötigen Trainingsdaten ist bei Deep Learning sehr hoch – erst recht bei einer komplexen Aufgabenstellung wie dem Sprachverständnis. Zusätzlich sind die Modellarchitekturen selbst immer besser (und komplexer) geworden. Welche neuen Ansätze hier besonders vielversprechend sind, erläutern wir weiter unten.
Vielleicht haben Sie den Innovationssprung auch schon selbst in Ihrem Alltag erlebt. Wenn Sie mit Siri oder Alexa sprechen, bei WhatsApp Nachrichten diktieren oder Texte mit DeepL übersetzten, ist NLP am Start.
Bei NLP geht es um die Verarbeitung menschlicher Sprache. Die Verarbeitung lässt sich in Teilbereiche mit unterschiedlichen Aufgabenstellungen unterteilen. Verwendete KI-Methoden, Modellarchitekturen und Trainingsparadigmen hängen von der zu lösenden Aufgabenstellung ab. Die Abbildung zeigt, wie breit das Gebiet NLP gefächert ist.
Künstliche Intelligenz & Natural Language Processing - Begriffe und ihre Relationen • Grafik: plusmeta GmbH
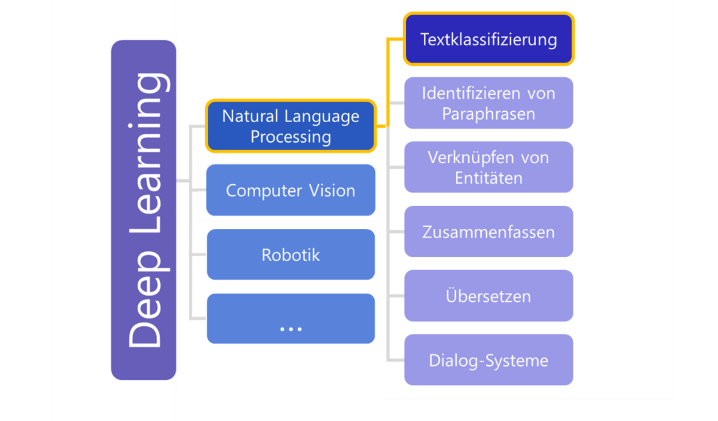
Bei den Anwendungsfällen von plusmeta ist das Ziel, dass die KI Texte aus Technischer Dokumentation einer passenden Klasse zuordnet. Auf Dokumentebene kann das z. B. eine Dokumentart sein. Wenn wir uns Dokumentationsbausteine (Topics) anschauen, können wir eine Informationsart oder die beschriebene Produktlebenszyklusphase bestimmen. Diese Aufgabe nennt sich „Textklassifizierung“. Damit die Texte den Klassen korrekt zugeordnet werden können, muss der Computer den Text zunächst einmal „verstehen“.
Aber wie versteht eine KI bzw. ein Computer eigentlich Text? Dafür wird ein Language Model (Sprachmodell) benötigt.
Die passende Form: Sprachmodelle und Embeddings
In Sprachmodellen transformieren Algorithmen unstrukturierte, natürliche Sprache in eine computerlesbare Form. Dazu werden die Texte segmentiert bzw. in Token zerlegt. Bei diesem Vorgang werden die Wörter in ihre Grundform gebracht, sodass grammatikalische Wortanpassungen (z.B. Flexionen) keinen Unterschied mehr machen.
Die enthaltenen Informationen werden in numerische Repräsentationen umgewandelt. Für diese Transformation gibt es unterschiedliche Vorgehensweisen, die die Komplexität des entstehenden Modells beeinflussen. In einfacheren Modellen wird jedem Wort ein diskreter Wert zugewiesen (Bag-of-Words). Synonyme und Schreibweisen müssen durch manuelles Eingreifen zusammengeführt werden. Die Textklassifikation wird hier über einen Abgleich der Klassen mit den im Index enthaltenen Wörtern realisiert.

Komplexere Modelle nutzen Embeddings für die Repräsentation der Wortbedeutung. D.h. es werden Vektoren gebildet, die die semantische Bedeutung eines Wortes beinhalten. Die Anzahl der Dimensionen hängt von der Komplexität des Modells ab. Ähnliche Worte wie „groß“ und „klein“ liegen im Vektorraum näher beieinander als die Worte „klein“ und „Tisch“. Ebenso können Wortbeziehungen dargestellt werden, sodass „Berlin“ zu „Deutschland“ in ähnlicher Beziehung zueinander stehen wie „Madrid“ zu „Spanien“.
Beispiele in Anlehnung an: Barthel (2020) • Grafik: plusmeta GmbH
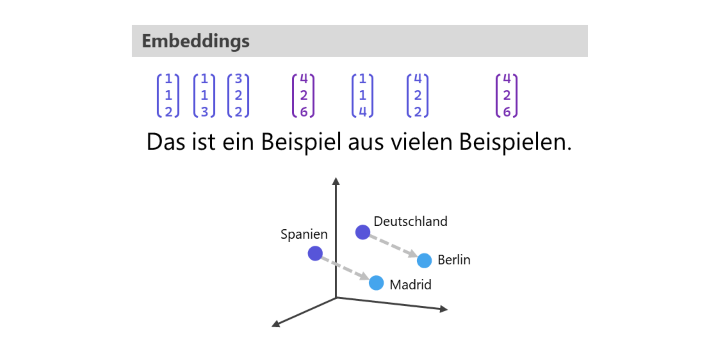
Außerdem erfassen moderne Language Models darüber hinaus den Kontext eines Wortes. Das heißt, sie betrachten nicht nur das Wort selbst, sondern auch den Text vor und nach einem Wort und berücksichtigen diesen für die Erstellung des Wort-Embeddings. Dass der Kontext entscheidend sein kann, wird bei mehrdeutigen Worten, Verneinungen, Ironie etc. deutlich. Eine Bank kann je nach Kontext der Ort zum Geld abheben oder eine Sitzgelegenheit im Park sein.
Die Embeddings werden gelernt, indem das Sprachmodell mit großen Mengen Text trainiert wird. In den Texten werden jeweils einzelne Wörter maskiert. Das Modell trainiert sich dann selbst, d.h. es passt die Gewichtungen im neuronalen Netz so an, dass es die maskierten Wörter richtig vorhersagt. Nach so einem Training weiß das Modell z.B., dass das Wort „blühen“ dem Wort „Blume“ mit höherer Wahrscheinlichkeit folgt, als das Wort „kommunizieren“.

Ok, dann kann das Modell schonmal mit Sprache umgehen. Können wir jetzt jeden beliebigen Text mit dem Modell klassifizieren bzw. jede beliebige Frage beantworten?
Pretraining und Finetuning
Die Antwort lautet „nein“. Dem Modell fehlt noch das Wissen zum Lösen spezifischer Aufgaben. Dieses Wissen kann in einem Finetuning aufgebaut werden. Es gibt dafür verschiedene Ansätze.
Im klassischen Finetuning nutzt man korrekt gelabelte Beispiele, um dem Modell eine spezifische Aufgabe beizubringen. Das Modell bekommt dabei einen neuen Output-Layer, der die spezifische Frage beantwortet. Innerhalb des Modells werden ggf. die Gewichte für die neue Aufgabe angepasst. Diesen Trainingsprozess haben wir in unserem ersten Blogartikel dieser Serie genauer beleuchtet.
Training für spezifische Aufgaben • Grafik: plusmeta GmbH
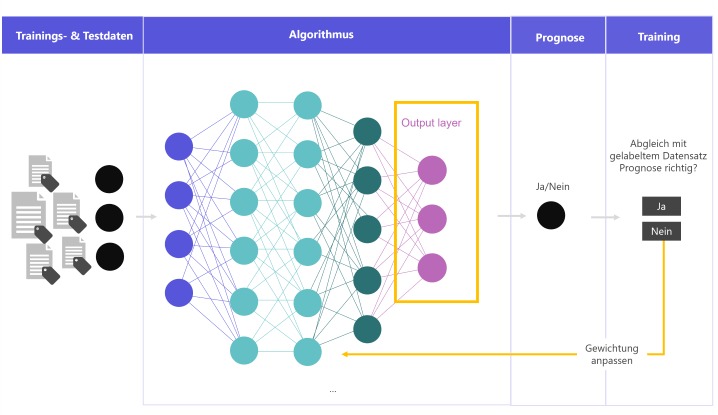
Durch so ein Finetuning wird das gesamte Modell auf die neue Aufgabenstellung spezialisiert. Wenn ein Modell im Pretraining beispielsweise auf einem allgemeinen Textkorpus trainiert wurde, kann das Modell im Finetuning die Erkennung Technischer Texte lernen, wenn es mit Technischen Texten trainiert wird. Die wahrscheinlichen Wortfolgen sind beispielsweise in Romanen anders als in Technischen Texten. Dementsprechend passen sich die Gewichte im Modell an. Das Modell ist danach auf Technische Texte „eingestellt“. Außerdem können konkrete Aufgabenstellungen gelernt werden, z.B. die der Klassifizierung der Technischen Texte.
Die Systematik aus Pretraining und Finetuning hat man sich vom menschlichen Lernen abgeschaut.
Transfer Learning
Menschen lernen sehr schnell, indem sie bei neuen Erlebnissen vorhandenes Wissen nutzen. Wir erkennen Muster wieder, bilden Assoziationen und können Ableitungen machen. Dieser Idee folgt das Transfer Learning beim Finetuning: bereits erworbenes, vorhandenes Wissen nutzen, um neuen Aufgaben zu lösen.
Traditionelles und Transfer Learning im Vergleich • Grafik: plusmeta GmbH
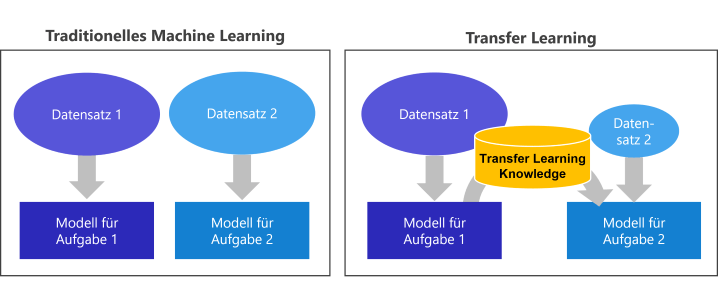
Für ein klassisches Finetuning werden sehr viele Daten benötigt. In unseren Forschungsprojekt hatten wir zwar Daten von unterschiedlichen Unternehmen. Um ein Modell mit Millionen Neuronen sinnvoll anzupassen, braucht man aber tausende bis zehntausende Beispiele.
Zum Glück kennt die neuer KI-Forschung auch Methoden, um mit weniger Trainingsdaten auszukommen.
Zero-Shot-Learning
Beim Zero-Shot-Learning wird der Ansatz des Transfer Learning auf die Spitze getrieben. Der Zero-Shot-Ansatz verwendet keine eigenen Daten für ein Training, sondern ein bereits trainiertes Modell (pretrained und finetuned) direkt für den eigenen Anwendungsfall.
Durch das Pretraining hat das Modell die grundsätzliche Struktur der Sprache erlernt. Zusätzlich wurde es im Finetuning auf die spezifische Aufgabe der Natural Language Inference (NLI) trainiert. Auf diese Weise feinjustierte Modelle erkennen, ob zwei Inhalte eine ähnliche semantische Aussage machen bzw. logisch zueinander passen.
Ein solches Modell kann für beliebige Sätze bestimmen, ob sie:
- die gleiche Bedeutung haben (Entailment),
- neutral zueinanderstehen (Neutral) oder
- Gegensätze sind (Contradicition).
Die Klassifikationsaufgabe wird beim Zero-Shot-Learning in eine Vergleichsaufgabe umgewandelt. Für jeden zuordenbaren Wert aus der Klasse wird ein Vergleich angestellt. Dazu wird das jeweilige Label in einen Satz eingebettet und dann dem zu klassifizierenden Text gegenübergestellt. Der Beispielsatz wird Hypothese genannt. Für Erstellung der Hypothesen gibt es weitere Ansätze, z. B. kann auch eine Label-Definition, eine Umschreibung oder einen Prototyp gegenübergestellt werden.
Zero-Shot-Learning • Grafik: plusmeta GmbH
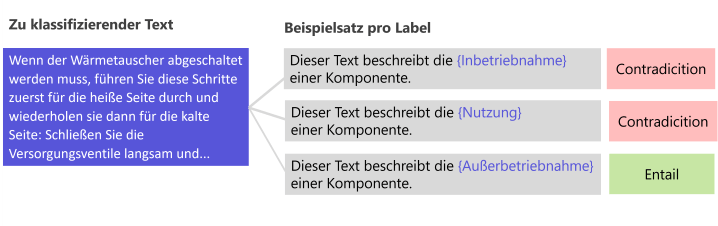
Das Paar, welches die höchste Ähnlichkeit aufweist, wird als das korrekte Label ausgegeben. Auf diese Weise können auf allgemeinen Texten verfeinerte Modelle verwendet werden, ohne dass ein weiteres Fine Tuning notwendig ist, da die erlernte Aufgabe gleichbleibt.
Wenn die Ergebnisse beim Zero-Shot-Learning noch nicht ausreichend genau sind, lässt sich mit dem Few-Shot-Learning sehr gut darauf aufbauen.
Few-Shot-Learning
Few-Shot-Learning basiert auf dem gleichen Prinzip wie das Zero-Shot-Verfahren. Zusätzlich werden einige Daten verwendet, um ein Modell auf die spezifischen Daten zu trainieren.
Wie beim Zero Shot wird der zu klassifizierende Text einem Satz gegenübergestellt. Alle Paare werden gelabelt ins Training genommen. Der Trainingsdatensatz wird außerdem noch weitere vergrößert, indem auch die negativen Beispiele für das Training genutzt werden. Bei 3 zu vergebenden Label hat man ein passendes Label und 2 negative Beispiele. Daher gibt es pro zu klassifizierenden Text insgesamt 3 Trainingsbeispiele. Der Trainingsdatensatz ist nun also dreimal größer. Diese künstliche Erhöhung des Datensatzes verspricht bessere Ergebnisse.
Welche Ergebnisse wir mit den Ansätzen bei der Klassifizierung Technischer Dokumentation erzielen konnten, verraten wir im letzten Teil unserer Blogserie.
Fassen wir die die wichtigsten Punkte kurz zusammen: Damit ein Computer Sprache verarbeiten kann, wird diese in eine strukturierte numerische Form transformiert, die die Bedeutung eines Wortes kontextabhängig repräsentiert (Embeddings). Es gibt umfangreiche Language Models, die mit riesigen Datenbeständen dieses grundsätzliche Sprachverständnis erlernt haben. In Finetunings lernen die Modelle spezifische Aufgaben zu lösen. Zero-Shot- und Few-Shot-Learning sind zwei moderne Ansätze, die mit dem Transfer bereits gelerntes Wissen und einer Umstellung der Aufgabe ohne bzw. mit weniger Trainingsdaten auskommen.
Sie wollen mehr darüber erfahren, wie Sie mit plusmeta Technische Dokumentation klassifizieren können? Dann vereinbaren wir gerne eine Demo.
In unseren Blogartikeln versuchen wir komplexe Technologien einfach und verständlich zu erklären. Dazu sind teilweise starke Vereinfachungen sinnvoll. Wenn Sie technischer und tiefer in die Materie einsteigen wollen, empfehlen wir Ihnen die Veröffentlichung unserer KI-Expert:innen Alina Cartus und Maximilian Both.
Quellen:
- Jurafsky, D. u. Martin, J. H.: Speech and language processing. An introduction to natural language processing, computational linguistics, and speech recognition. Prentice Hall series in artificial intelligence. Upper Saddle River, NJ: Prentice Hall Pearson Education Internat 2009
- Xian, Y., Lampert, C.; Schiele, B.; Akata, Z. [2020]: Zero-Shot Learning — A Comprehensive Evaluation of the Good, the Bad and the Ugly
- Peng, B., Zhu, C., Li, C., Li, X., Li, J., Zeng, M. u. Gao, J. (2020): Few-shot Natural Language Generation for Task-Oriented Dialog,
- Barthel, S. (2020): Grundsätze moderner Textklassifizierung für Machine Learning: Word Embeddings. Einstieg in das Machine Learning: Teil 1 https://entwickler.de/python/grundsatze-moderner-textklassifizierung-fur-machine-learning-word-embeddings
- Natural Language Processing, Blogartikel von Maximilian Both https://www.tecislava.com/categories/nlp
- Cartus, Alina (2021): Die Analyse der Einbindung von Metadaten in ein Language Model zum verbesserten Sprachverständnis von Task Oriented Dialogue Systems für TGA-Komponenten. Bachelorthesis
Ihre Frage zu NLP wurde nicht beantwortet? Dann schreiben Sie uns gerne eine E-Mail an hallo@plusmeta.de!