

Was ist Deep Learning?


von Eva-Maria Wolf
Okt. 04, 2022


Eintauchen in die Welt des Deep Learning • Grafik: plusmeta GmbH, Viktoria Kurpas/Shutterstock.com
In unserem Forschungsprojekt DEEEP, das von Wirtschaftsministerium Baden-Württemberg gefördert wird, erweitern wir unsere plusmeta Plattform um eine Deep-Learning-Komponente.
In diesem Blogartikel machen wir einen „Deep-Dive“ und erklären, was Deep Learning ist und wie es funktioniert. Dieser Blogbeitrag ist der erste einer Blogserie. In weiteren Blogbeiträgen tauchen wir weiter in spannende Deep-Learning-Themen ein, die wir in unserem Forschungsprojekt bearbeiten.
Heute starten wir mit den Grundlagen. Um zu verstehen, was Deep Learning ist, werfen wir zuerst nochmal einen Blick aufs große Ganze: Was ist Künstliche Intelligenz und in welchem Verhältnis steht sie mit Deep Learning?
Was ist Künstliche Intelligenz? – Ein Überblick
Künstliche Intelligenz (KI) ist ein Teilgebiet der Informatik, das versucht menschliches Denken und Handeln zu imitieren. Mit einem pragmatischen Blick auf Künstliche Intelligenz kann man auch sagen, dass Computerprogramme dann intelligent sind, wenn sie ein intelligent wirkendes Ergebnis produzieren.
Aus diesem Blinkwinkel betrachtet untergliedert sich KI in zwei Teilgebiete: Machine Learning und Regelbasierte Verfahren.
Künstliche Intelligenz - Begriffe und ihre Relationen • Grafik: plusmeta GmbH
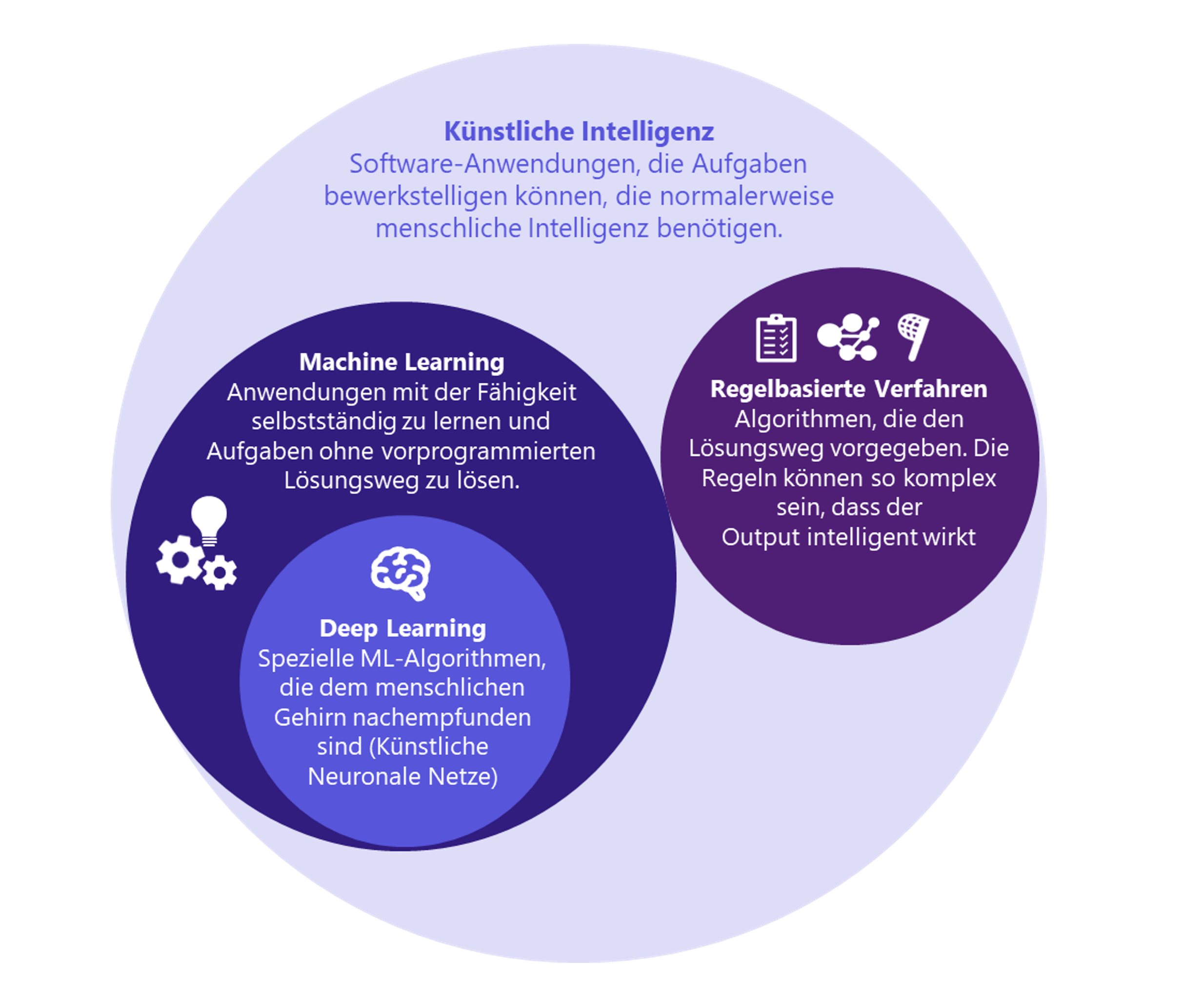
Regelbasierte Verfahren – komplex verknüpfte Regelsets
Regelbasierte Verfahren sind komplexe Algorithmen. Sie lösen Aufgaben auf Basis vorgebebener Lösungswege nach Mustern wie „wenn x eintritt, mach‘ y“. Diese Regeln können so komplex kombiniert und verschachtelt sein, dass am Ende ein intelligent wirkendes Ergebnis herauskommt. Zu den Regelbasierten Verfahren zählen „Label Matching“, „Auswertung von Knowledge Graphen“ und „Pattern Matching“.
Einen Einblick in die Funktionsweise und die Einsatzmöglichkeiten unserer Regelbasierten KI-Verfahren haben wir in einem Interview mit unserem Partner Quanos geben.
In plusmeta werden viele Metadaten regelbasiert vergeben, da hier lediglich die Listen der zu vergebenden Werte (Label Matching), ein Knowledge Graph mit Abhängigkeiten und Zusammenhängen oder ein Pattern zum Finden bestimmter Formate (Pattern Matching) benötigt wird.
Machine Learning – wenn Computer Lernen lernen
Beim Machine Learning lernt der Computer selbstständig dazu. Der Lösungsweg ist nicht explizit vorprogrammiert. Machine-Learning-Anwendungen lernen aus „Erfahrung“ bzw. aus historischen, statistischen Daten. Die Basis bildet ein Modell, das für die spezifische Aufgabenstellung trainiert wird. Wir werfen weiter unten im Abschnitt zum „Training“ einen genaueren Blick auf diese Modelle und das Lernen der KI.
Machine Learning hat wiederrum Teilgebiete. Zu diesen gehört auch das Deep Learning. Andere Machine-Learning-Verfahren sind beispielsweise selbstlernende Entscheidungsbäume, bei denen KI durch den Baum leitet, sowie die Lineare Regression. Bei der Linearen Regression schreibt die KI die Ergebnisse aus der Vergangenheit fort und macht so Prognosen.
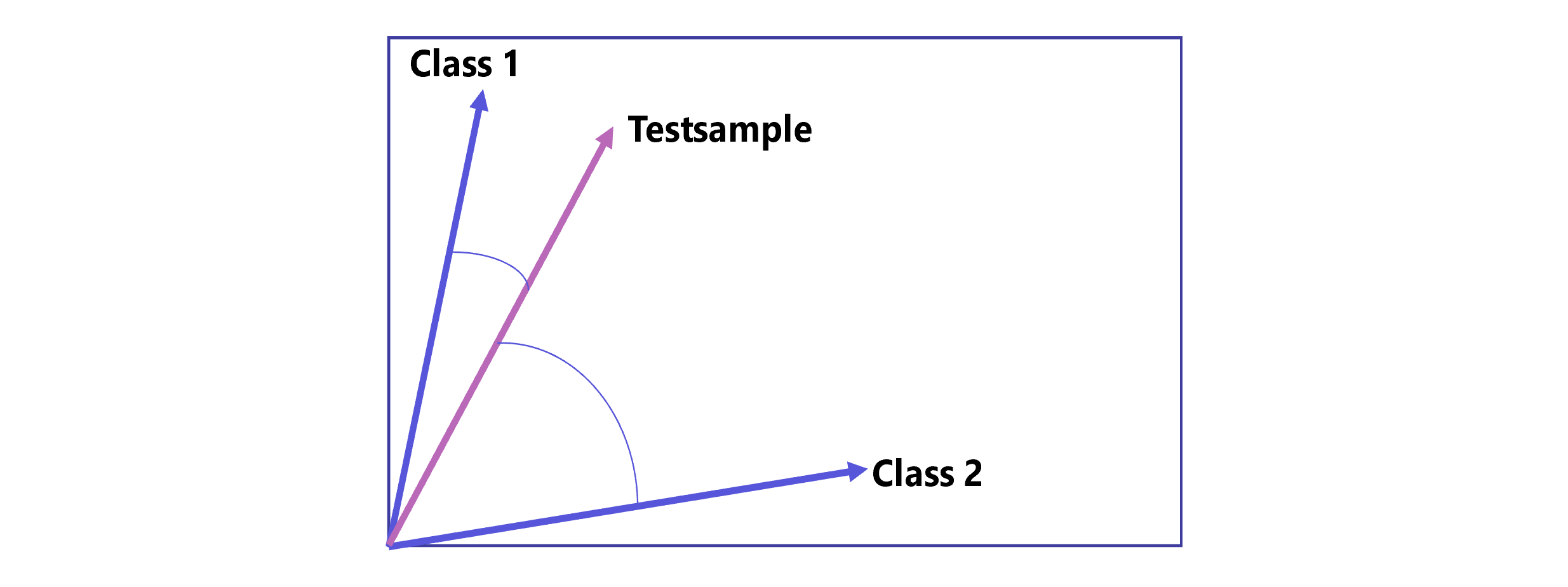
Ein weiteres Machine-Learning-Verfahren basiert auf einem Vector Space Model. Dieser Ansatz verbirgt sich hinter dem derzeit in plusmeta eingesetzten Machine Learning. Hier wird aus vielen klassifizierten Beispielinhalten jeweils ein repräsentativer Vektor pro Wert gebildet. Neue, unklassifizierte Inhalte bekommen den Wert als Prognose, zu dem ihr Vektor am nächsten liegt.
Der Vektor der neuen Beispieldaten liegt hier näher an „Class 1“ als an „Class 2 • Grafik: plusmeta GmbH
Deep Learning – Gehirnähnliche Modelle
Und da wären wir nun endlich beim Deep Learning. Deep Learning ist eine spezielle Form des Machine Learnings. Die Besonderheit am Deep Learning ist die Architektur der Modelle. Sie sind dem menschlichen Gehirn nachempfunden. Die Künstlichen Neuronalen Netzwerke sind aus vielen künstlichen Neuronen aufgebaut, die miteinander vernetzt sind. Dadurch entstehen Schichten. An jedem Knoten wird eine einfache Entscheidung getroffen. Durch die Verkettung der Entscheidungen entsteht ein komplexes System.
Übersicht über Modellaufbau und Training beim Deep Learning • Grafik: plusmeta GmbH in Anlehnung an Deep-Learning-Whitepaper von Dirik (2018), Tier-Symbole: flaticon.
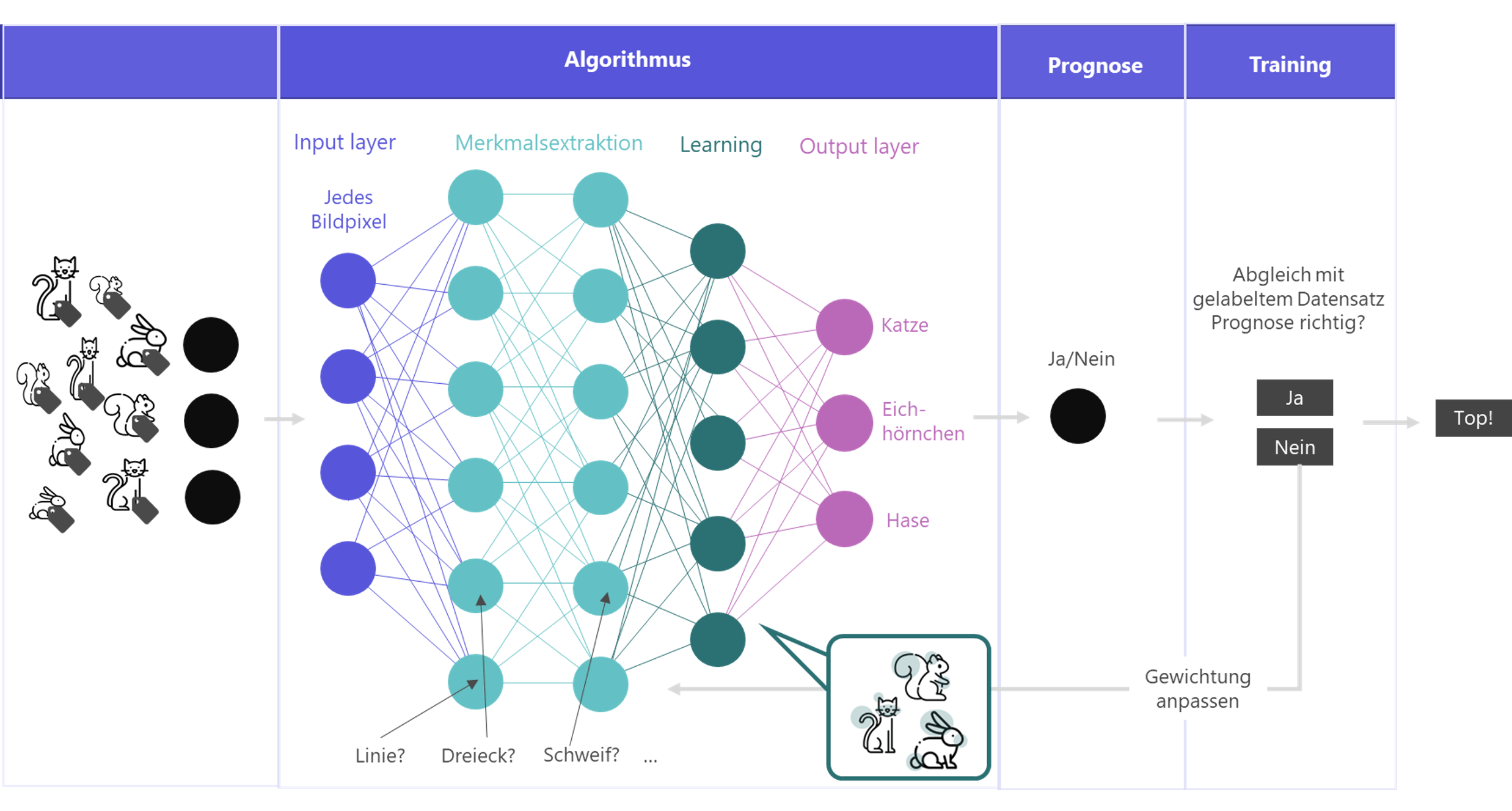
In der ersten Schicht werden alle Eingabeinformationen verarbeitet, z. B. alle Pixel eines Bilds. In den folgenden Schichten werden zunächst abstraktere Aufgaben erledigt, wie das Erkennen von Linien und Formen. Auf späteren Schichten werden die Aufgaben konkreter und komplexer. Die Schichten werden auch „Hidden Layer“ genannt, denn was genau in welcher Schicht passiert, ist eine Blackbox. Die KI findet selbst die relevanten Merkmale und Entscheidungen, die zu treffen sind. Welche Merkmale in welchem Neuron bzw. welcher Schicht berücksichtigt werden, bleibt also Geheimnis des Modells.
Ganz am Ende steht ein Output Layer. Er gibt Antwort auf die eingangs gestellte Frage, zum Beispiel „Zeigt das Bild ein Eichhörnchen?“. Vereinfacht kann man sich die Entscheidungen an allen Neuronen als binäre Ja/Nein-Antwort vorstellen. Tatsächlich werden allerdings Wahrscheinlichkeiten ausgegeben, z. B. es handelt sich bei dem Bild mit einer Wahrscheinlichkeit von 87% um ein Eichhörnchen.
Anschließend prüft das Modell gegen klassifizierte Trainingsdaten, ob seine eigne Prognose stimmt. Wenn das der Fall ist, top! Wenn nicht, geht die Information in Form einer Gewichtung zurück ins Modell. Der Algorithmus lernt also aus seinen eigenen Fehlern und korrigiert sich mit jedem Durchlauf.
Aber wie kann so ein Modell entstehen? Es muss trainiert werden!
Das Training - Von nichts kommt nichts
Für das Training kommen unterschiedliche Paradigmen in Fragen. Je nach Aufgabenstellung und zu erzielender Modellarchitektur wird die Trainingsstrategie ausgewählt. Die drei wichtigsten Vertreter sind das Supervised Learning (überwachtes Training), das Unsupervised Learning (unüberwachtes Training) und das Reinforcement Learning (bestärkendes Lernen).
Supervised Learning: Im überwachten Training zeigt man der KI von Hand gelabelte Beispiele. Aus den Beispielen und daran gesetzten Klassifikationen leitet sich die KI entscheidende Merkmal für die jeweiligen Klassen ab. Im Fall von „klassischer“ Textklassifizierung können das zum Beispiel typische Wortgruppen sein. Diese Trainingsart kommt auch heute schon in der plusmeta Plattform zum Einsatz.
Reinforcement Learning: Beim bestärkenden Lernen bekommt die KI eine Zielsetzung vorgeben und Belohnung, wenn sie gute Ergebnisse erzielt. Die KI versucht sich selbst so weit zu optimieren, dass sie möglichst viele Belohnungen bekommt, z. B. in Form von Punkten.
Unsupervised Learning: Im unüberwachten Training werden keine klassifizierten Trainingsdaten benötigt. Denn hier ist auch die Aufgabenstellung anders. Die KI soll die Daten gruppieren. Wir geben vor, in wie viele Gruppen geteilt werden soll. Die KI entscheidet, welche Merkmale zur Gruppierung in diese x Gruppen geeignet sind. Im Anschluss kann exploriert werden, nach welchen Kriterien die KI wahrscheinlich sortiert hat.
Die unterschiedlichen Trainingsparadigmen werden im Blog tecislave von unserem KI-Experten Maximilian Both anschaulich erklärt. Ein wichtiges Fazit zum Thema „Training“: Die KI kann nur das, wofür sie trainiert wurde. Im Fall vom Supervised Learning heißt das z. B., dass die KI keine Hasen auf Bildern erkennen kann, wenn sie keine Beispiel-Hasenbilder gesehen hat.
Schicht für Schicht ans Ziel
Von Deep Learning spricht man, wenn es mehrere Hidden Layer gibt. Damit solche Hidden Layer entstehen können, sind sehr viele Trainingsdaten notwendig. Gängige Sprachmodelle für die deutsche Sprache wurden beispielsweise mit allen deutschsprachigen Wikipedia-Artikeln trainiert.
So viele Trainingsdaten hat man in den meisten Projekten nicht. Daher arbeitet man beim Deep Learning in der Regel mit vortrainierten Modellen und bringt diesen lediglich noch das Wissen für die neue Aufgabenstellung bei.
Durch aufgabenspezifische Trainings entstehen neue Schichten im Modell. Beispielsweise können hier die typischen Wortgruppen für die Produktlebenszyklusphase „Betrieb“ erkannt werden oder die Merkmale gefunden werden, anhand derer man auf einem Bild einen Schaltplan erkennt.
Die vielen Schichten ermöglichen komplexe Aufgabenstellung wie Bilderkennung und bei Sprachverständnis nicht nur einzelne Wörter, sondern auch den Kontext, in dem sie stehen, zu berücksichtigen.
Alles eine Frage des Aufbaus - Modellarchitektur
Neben der Trainingsstrategie ist auch die Modellarchitektur entscheidend dafür, was für Arten von Aufgaben eine KI prinzipiell lösen kann. Bei dem oben beschriebenen Beispiel handelt es sich um ein Convolutional Neural Network (CNN). Solche Modelle kann man für Klassifikationsaufgaben nutzen. Sie können Metadatenzuweisungen vorschlagen, Bilder erkennen oder Sprache verstehen. Zum Übersetzen von Texten kommen dagegen Sequenzmodelle zum Einsatz. Texte generieren können Generativ Adversarial Networks.
Schon anhand der unterschiedlichen Modelle wird deutlich, wie breit das Aufgabenspektrum ist, für das KI einsetzbar ist. Man muss nur das richtige Modell haben und gut trainieren. 😊
Werfen wir zum Abschluss nochmal einen Blick auf die Unterschiede zwischen konventionellem Machine Learning und Deep Learning, um den Begriff vollständig abzugrenzen.
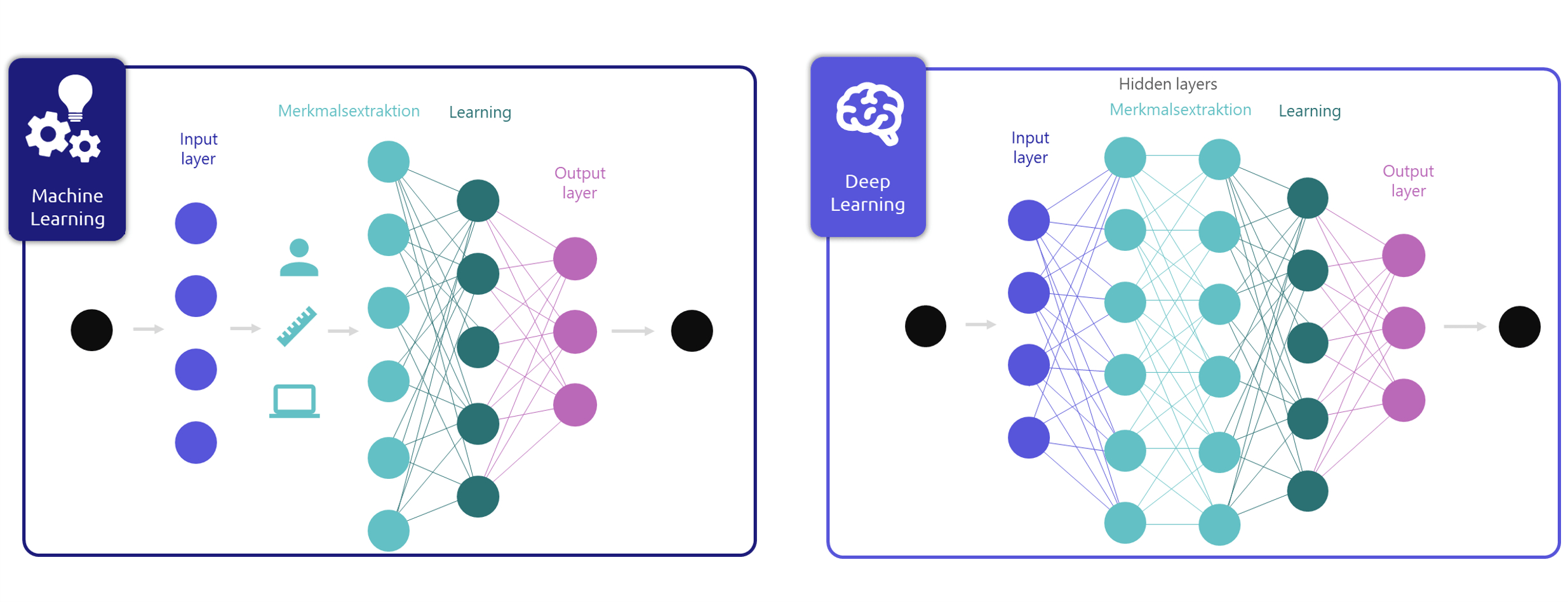
Konventionelles Machine Learning vs. Deep Learning
Die Merkmalsextraktion ist der Vorgang, bei dem eine leichter verarbeitbare Darstellung der Daten erzeugt wird.
Beim konventionellen Machine Learning ist die Merkmalsextraktion durch Menschen oder von Messparametern beeinflusst. Beispielsweise wird für Textklassifizierungsaufgaben der Text in Fragmente zerlegt. Wie viele Wörter so ein Fragment, das auch n-Gramm genannt wird, enthält, kann man konfigurieren. „n“ bestimmt dabei die Wortzahl pro Fragment. Des Weiteren kann die Gewichtung der n-Gramme angepasst werden. So können z. B. besonders Bedeutungstragende Wörter höher gewichtet werden. Bei der Gewichtung ist eine Anpassung an die zu verarbeitende Textsorte sinnvoll. In unserem Fall ist die Gewichtung auf die Besonderheiten der Technische Dokumentation angepasst (Gewichtung entwickelt in der Dissertation von Dr. Jan Oevermann).
Beim Deep Learning dagegen ist die Merkmalsextration Teil des Algorithmus und wird von der KI übernommen. Das heißt aber auch, dass wir keinen Einfluss darauf haben, was die KI als relevante Merkmale aus den Trainingsdaten extrahiert und lernt.
Der Unterschied zwischen konventionellen Maschine Learning und Deep Learning liegt in der Merkmalsextraktion und der Anzahl der verborgenen Schichten. • Grafik: plusmeta GmbH in Anlehnung an Aporras
Und welches Fazit können wir nun ziehen aus der Betrachtung?
Deep Learning ist ein weites Feld mit vielen unterschiedlichen Anwendungsmöglichkeiten. Die Aufgabenstellung beeinflusst die Modellform und die Trainingsart. Man braucht ausreichend Trainingsdaten und viel Rechenpower.
Im nächsten Beitrag unserer DEEEP-Blogserie erfahren Sie, wie Künstliche Intelligenz Sprache versteht. Wir gehen dabei auch auf die Frage ein, wie wir in unserem Forschungsprojekt mit modernen Ansätzen aus dem Bereich Natural Language Processing versuchen, die Trainingsdatenmenge möglichst gering zu halten.
Anmerkung zum Schluss
Die Modelle und Verfahren sind teilweise stark vereinfacht dargestellt. In diesem Betrag geht uns vor allem darum die Prinzipien für unsere Anwender:innen, die vor allem aus dem Bereich Technische Redaktion kommen, verständlich darzustellen. KI-Fachleuten und Personen, die tiefer in Themen einsteigen möchten, empfehlen wir den Blog von unserem KI-Experten Maximilian Both sowie die wissenschaftlichen Veröffentlichungen unserer KI-Expert:innen Alina Cartus, Dr. Jan Oevermann, Julian Höllig und Maximilian Both.
Quellen:
- Aporras (2019): What is the difference between Deep Learning and Machine Learning? (https://quantdare.com/what-is-the-difference-between-deep-learning-and-machine-learning/)
- Heller, Martin (2022): Was ist Deep Learning? (https://www.computerwoche.de/a/was-ist-deep-learning,3549921)
- Manning, Christopher (2020): Artificial Intelligence Definitions. https://hai.stanford.edu/sites/default/files/2022-06/HAI_Terms_6_22.pdf
- Norvig / Russell (2021): Artificial Intelligence: A Modern Approach, Global Edition. 4 Auflage
- Oevermann, Jan (2019): Dissertation : Optimierung des semantischen Informationszugriffs auf Technische Dokumentation.
- Dirik, Iskender (2018): Was ist den bitte Deep Learning? Whitepaper (https://news.microsoft.com/de-de/deep-learning-whitepaper/)
- Hötter, Johannes; Warmuth, Christian (2020): OpenHPI Kurs „Künstliche Intelligenz und maschinelles Lernen für Einsteiger“ (https://open.hpi.de/courses/kieinstieg2020)
Sie haben noch Fragen? Schreiben Sie uns eine E-Mail an hallo@plusmeta.de!